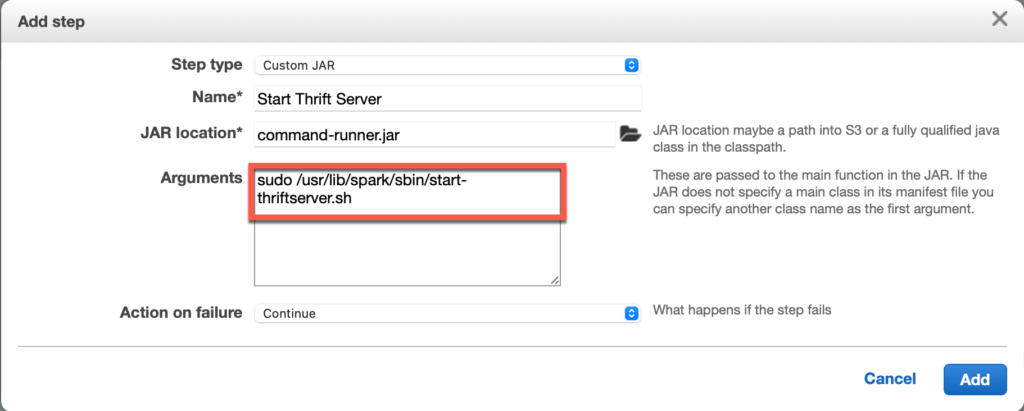
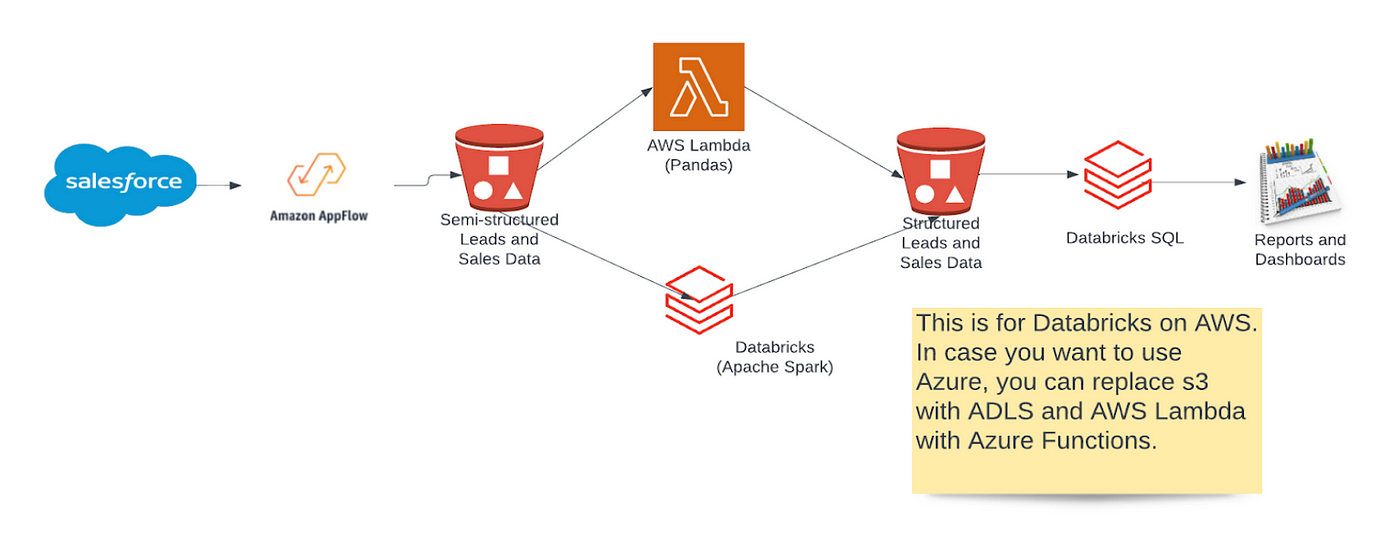
Is your organization facing barriers while dealing with Apache Spark deployments or on-premises Apache Hadoop? Is your team really struggling with over-provisioning resources to control task variability? Do you invest a long time in maintaining rapidly changing open-source software innovation?
Then, your organization is not lonely. Big data and machine learning migration to AWS and Amazon EMR can produce many leads over on-premises deployments. It involves an increase in agility, separation of computing and storage, persistent and resilient storage, and managed services providing up-to-the-minute, simple environments to develop and operate big data applications.
We need to be careful in decision-making while migrating big data and analytics workloads from on-premises to the cloud. Many customers successfully migrate their big data from on-premises to Amazon EMR with our help. We are keeping here a step-by-step EMR Migration process based on the successful case studies which will also showcase best practices for:
- Migrating data, applications, and catalogs
- Using persistent and transient resources
- Configuring security policies, access controls, and audit logs
- Estimating and minimizing costs, while maximizing value
- Leveraging the AWS Cloud for high availability (HA) and disaster recovery (DR)
Organizations present far and wide are aware of the power of data analytics and processing frameworks, like Apache Hadoop. Still, there are challenges and difficulties while implementing and functioning these frameworks in data lake environments deployed on-premises.
AWS EMR migration assists organizations to shift their Hadoop deployments and big data workloads within our budget and timeline estimates.
There are significant downtimes and it is not financially viable while upgrading and scaling hardware to provision growing workloads on-premises. This has led the way for organizations to re-architect with the help of AWS EMR to build a modern system that is high-performing, safe, sustainable, and cost advantageous.
Challenges faced because of On-Premises Hadoop data lakes
Scalability for organizations with the help of Hadoop deployed on-premises will be the biggest challenge as it includes the purchase of additional hardware. It is not adapted to elasticity and makes use of clusters for long periods of time as well. The costs concerning the workloads gradually increase because of the ‘always on’ infrastructure while the data recovery and widely available requires to be supervised manually.
Critical necessity for Organizations
- Flexible infrastructure and Easily scalable which can be provisioned fast based on the requirements.
- Admin dependency depletion with a completely managed service.
- Cost optimization with the ability to switch the infrastructure on and off based on workload demand.
- Innovative schemes for improved return on investment (ROI) in the long term.
- Inspecting new open-source technologies with spinning up sandboxes in actual time.
- Integrating cloud security with the help of the Hadoop ecosystem.
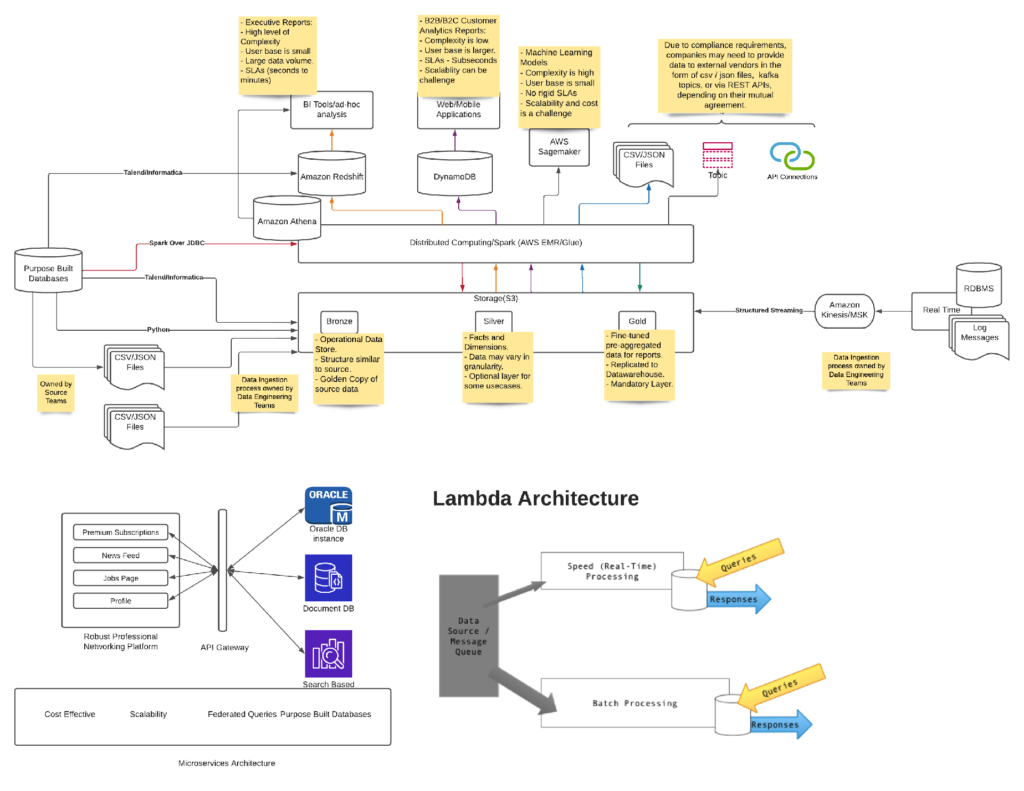
AWS Data Analytics – Reference Architecture Diagram:
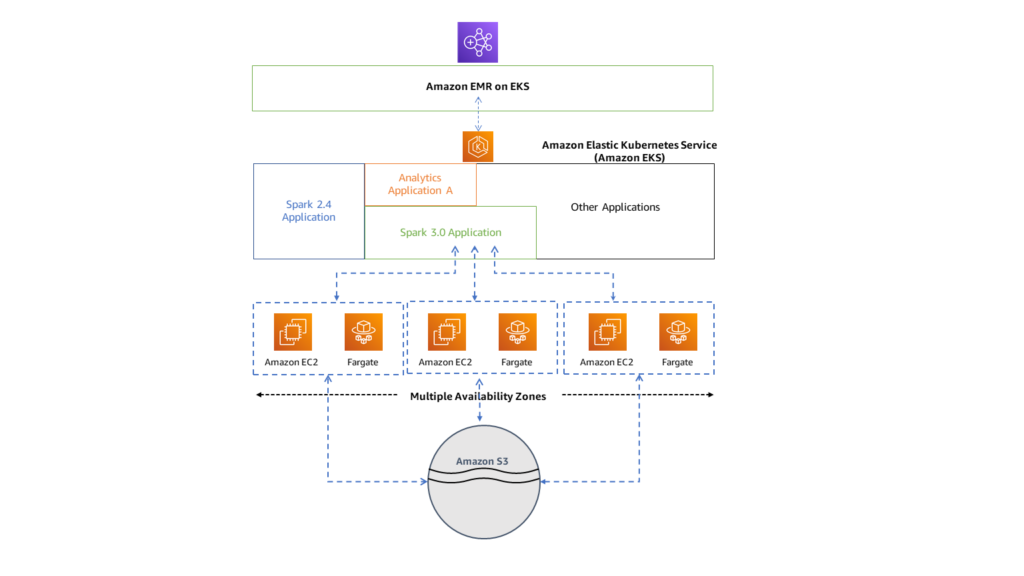
Benefits of AWS EMR Migration?
The primary considerations of organizations are data-driven insights and cost optimization to reach nearly zero idleness of workloads with quick business value. Below are some critical USPs of AWS EMR migration designs that can help organizations to execute the previously mentioned.
- Decoupling of the storage and compute systems.
- A seamless data lake environment with Amazon S3.
- A stateless compute infrastructure.
- Cluster capabilities that are consistent and transient.
- Cluster fragmentation is based on business units for improved isolation, customization, and cost allocation.
Enterprise Data Lake on AWS
Following technologies are listed which can be used during migration
- Low-cost storage using S3
- Ad-hoc analysis using Athena or Redshift
- Streaming pipelines using Kinesis or Kafka
- Operational Data Store using Dynamo DB
- Datawarehouse using Redshift
- Visualizations using Quicksight
- Orchestration using Step Functions or Airflow
- Other key AWS services like Lambda, API gateway, and SQS, etc.
Key Strategies for Hadoop to EMR Migration
Retire
Recognizing everything in your business environment which has the possibility to migrate lets you estimate the value of the product, application, or service. Detect all the users of each migration element and check what is being used and what is not. Finding out what you can retire will help in saving money on elements that should have been earlier phased out of use too.
Retain
A few elements of your environment may not migrate and are kept as it is. There are several grounds for the sake of maintaining an in-house element, like riding out the reduction value or the cost of migration is overpriced, and your company can maintain more value with the application or service. Keeping some IT aspects on-premise is chosen for a hybrid cloud service in demand.
Lift and Shift
This plan of action benefits companies to achieve Hadoop to EMR migration quickly to speed up shutting down their on-premises data center. This allows organizations to get rid of cost-intensive hardware upgrades. The lift and shift strategy assists organizations to keep their existing Hadoop segregated and classified by utilizing AWS S3. In addition to this, it also helps them in decoupling resources and limiting code transformations to a bare minimum. Code is moved to the cloud environment with the simple lift and shift of Hadoop to the EMR migration approach
Re-Platformization
The re-platform strategy for Hadoop to EMR migration permits organizations to enlarge their cloud migration benefits. This is done by making use of the entire set of features given by AWS EMR. With the help of this strategy, organizations can harmonize their workloads and infrastructure for cost-effectiveness, scalability, and accomplishment. Also, this strategy permits organizations to integrate their Hadoop ecosystem with cloud monitoring and security. Even though re-platform is like the lift and shift approach, it provides comparatively lesser optimizations when it comes to cloud features and offerings.
Refactor and Re-Architecting
Organizations get help to re-imagine their ecosystem of insights in the cloud with the strategy of re-architecting Hadoop on AWS EMR. It supports them normalize their data to a larger customer pool while lowering the time-to-insight. This can be attributed to the abilities of streaming analytics that supply organizations to self-service their demand while building greater capabilities.
The re-architect plan of action sorts out all the challenges faced by the organizations. It ranges from the survey of business priorities to building a cloud-based data platform. The strategy includes changing the architecture with the help of cloud-native services to increase performance, provision scalable solutions, and upgrade the cost-effectiveness of the infrastructure.
Summary
Apache Hadoop to AWS EMR migration is the best match for organizations with everlasting targets. With the help of this migration, organizations can re-architect their infrastructure with AWS cloud services such as S3, Athena, Lake Formation, Redshift, and Glue Catalog which are existing. Organizations that look for achieving simple, quick scalability and elasticity with finer cluster utilization must put forward AWS EMR migration. This also helps in realizing cost-efficient and executing a well-architected and well-designed solution.